Skip to content
Skip to content 
Can a confidential conversation with an Artificial Intelligence platform be subpoenaed and used to convict you in a court of law? A recent landmark ruling in the United States says yes.
Bradley Heppner, the former CEO of financial firm GWG Holdings, faced multiple federal charges, including conspiracy to commit securities fraud, wire fraud, making false statements to auditors, and falsifying corporate records. Following his indictment, Heppner input extensive, sensitive details of his case into Anthropic's AI assistant, Claude, generating a 31-page document detailing case analyses and prospective defense strategies.

Subsequent to a search warrant executed by the FBI, federal agents seized the AI chat logs directly from Heppner’s personal devices. US prosecutors moved to introduce these records into evidence to verify whether Heppner had concealed assets or information during the investigation.
On February 17, 2026, the U.S. District Court for the Southern District of New York (S.D.N.Y.) issued an official memorandum ruling that these 31 AI chat logs are not protected by attorney-client privilege or the work-product doctrine. Consequently, the prosecution was granted lawful access to introduce them as trial evidence.
I. Judicial Rationale: Why AI Communications Lack Privilege
Heppner’s defense counsel argued that the strategic consultations with Claude constituted privileged legal preparation and should be immune from government scrutiny. The court decisively rejected this argument, ruling that user inputs and AI outputs operate under the same evidentiary standards as a standard search engine log. The court outlined three primary justifications:
- Ineligibility of the Entity: Claude is an algorithmic model, not a licensed attorney. Attorney-client privilege is legally predicated on a trusted, qualified relationship between human professionals. Claude's terms of service explicitly disclaim providing formal legal counsel, invalidating any claim of a legally recognized retainer or agency relationship.
- Absence of a Reasonable Expectation of Confidentiality: Anthropic’s privacy policy expressly reserves the right to collect user inputs for model training and to disclose data to third parties, including government regulatory and law enforcement bodies. By agreeing to these terms, the user forfeits any "reasonable expectation of privacy" under the law.
- Nature of Use: Because the platform explicitly states it does not provide professional legal opinions, Heppner’s interactions were classified as independent pro se research utilizing a digital utility, rather than seeking counsel from a credentialed professional.

(source: U.S. Air Force)
II. Global Regulatory Landscape: Privacy Terms of 10 Major AI Platforms
Under standard cross-border legal frameworks, electronic data is a globally recognized category of statutory evidence. Unlike common-law jurisdictions, many civil-law systems lack a broad application of "attorney-client privilege" exemptions. If a party inputs admissions of guilt, structural corporate vulnerabilities, or operational execution steps into an AI, these logs can be legally collected as electronic evidence and directly leveraged in sentencing.
1. Model Training & Data Opt-Out Policies
- International Platforms: Across standard consumer tiers (excluding premium enterprise or dedicated API accounts), user inputs are activated for model optimization by default, requiring proactive manual intervention from the user to opt out.
- Domestic Platforms: Leading providers reserve the structural right to utilize user queries for algorithmic alignment, creating heightened data-discoverability risks during litigation.
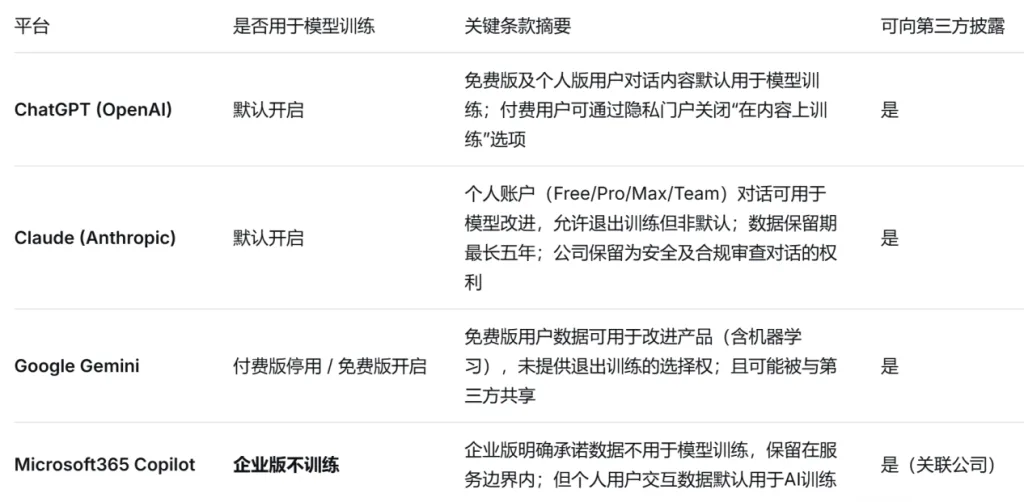
| Platform | Model Training Status | Key Structural Provision | Third-Party Disclosure |
| OpenAI ChatGPT | Enabled by default | Free tier inputs train models; paid tiers allow users to manually turn off "Chat History & Training". | Yes |
| Anthropic Claude | Enabled by default | Personal tier (Free/Pro/Team) data optimizes models; data retention lasts up to 5 years. | Yes |
| Google Gemini | Enabled by default | Free tier inputs are reviewed by human operators; enterprise tiers exclude training data by default. | Yes |
| Microsoft 365 Copilot | Disabled (Enterprise Only) | Commercial data protection ensures enterprise tenant data is never utilized for public LLM training. | Yes (Affiliates) |
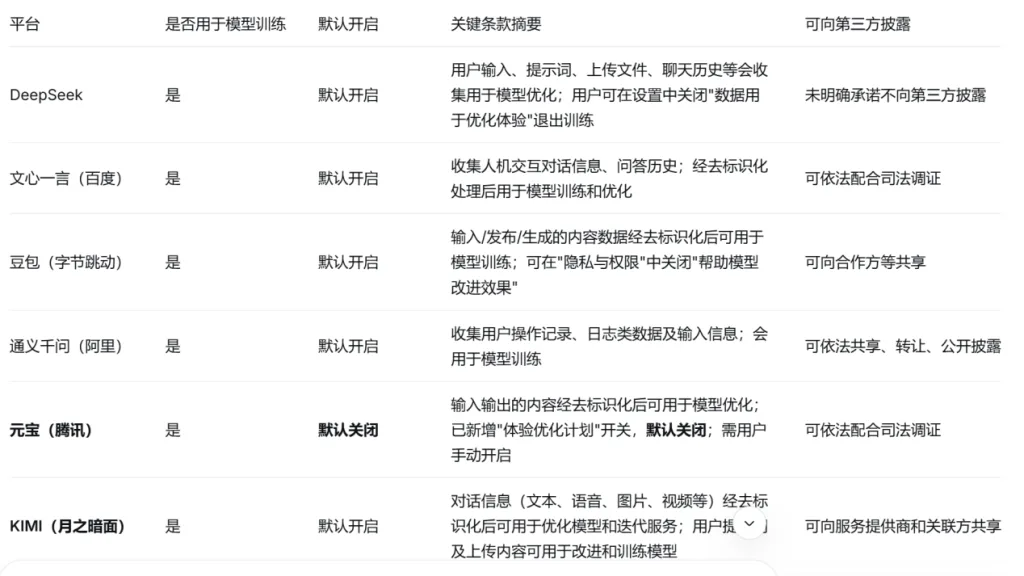
| DeepSeek | Enabled by default | User inputs, history, and uploaded files are used for fine-tuning; users can opt out via privacy settings. | Unspecified |
| Baichuan (Doubao) | Enabled by default | Inputs and operational metadata train models; adjustable via "Privacy and Permissions" dashboard. | Partners/Co-processors |
| Tencent Yuanbao | Enabled by default | Inputs optimize models; requires users to manually navigate settings to toggle off optimization. | Pursuant to judicial order |
| Alibaba Tongyi Qianwen | Enabled by default | System logs and conversational sequences train models; explicit exemptions apply via opt-out clauses. | Pursuant to judicial order |
| Moonshot AI (KIMI) | Enabled by default | Communications, documents, and rich media train models; users can toggle off features manually. | Affiliates & Service Providers |
| Baidu ERNIE Bot | Enabled by default | Collected dialogue data undergoes de-identification and anonymization protocols before system training. | Pursuant to judicial order |

(source:gov.uscourts.nysd)
2. Mandatory Disclosures Under Criminal Investigations
A comprehensive analysis of the privacy agreements across all ten major international and domestic platforms confirms a uniform compliance standard: Every platform reserves the right to disclose user data to law enforcement, national security, or regulatory agencies without user consent when executing a valid legal order.
- OpenAI (ChatGPT): Discloses records to comply with subpoenas, search warrants, or court orders, and to investigate potential terms-of-service violations or fraudulent activity. Subject to global regulatory scrutiny, including a May 2026 Office of the Privacy Commissioner of Canada (OPC) joint report finding data practices non-compliant prior to recent platform updates.
- Anthropic (Claude): Explicitly reserves the right to disclose records to regulatory authorities. This provision served as a foundational basis for the Heppner ruling. Furthermore, its designation under strategic supply chain frameworks exposes it to rigorous data disclosure oversight.
- Google (Gemini) & Microsoft (Copilot): Both platforms enforce strict compliance procedures requiring disclosure under valid legal processes across consumer and standard enterprise endpoints. Microsoft publishes annual transparency reports documenting government data access volume.
- Domestic LLMs (DeepSeek, Doubao, Yuanbao, Tongyi Qianwen, KIMI, ERNIE Bot): All operate under explicit statutory exemptions regarding user consent. Under local data security frameworks, platforms are legally mandated to cooperate without user authorization during criminal inquiries, national security threats, public interest exemptions, or asset freezing mandates (e.g., assisting in unfreezing over RMB 4 million in illicitly flagged deposits).
III. Strategic Takeaways for Enterprise Users & Legal Practitioners
- Enforce Strict Data Anonymization: Never input personally identifiable information (PII), banking credentials, sensitive trade secrets, or unmasked case details into public AI environments. Manually adjust platform configurations to opt out of data-retention and training programs.
- Deploy Enterprise-Grade, Zero-Retention Architectures: For corporate environments handling protected data, bypass consumer models entirely. Utilize enterprise instances or API endpoints that provide contractually guaranteed "Zero Data Retention" (ZDR) and explicitly exclude user inputs from model optimization pools.
- Recognize the Risk of Algorithmic Subpoenas: Understand that when case data is processed on an external server, it generates an enduring digital footprint. Under global regulatory compliance exemptions, regulatory and judicial bodies possess the authority to compel platforms to hand over these server-side logs during an active investigation.
- Mandate Professional Human Oversight: AI outputs must never be treated as definitive legal or professional authority. As shown in recent California appellate sanctions where an attorney was fined $10,000 for submitting 21 AI-fabricated precedents, all generative material must undergo rigorous verification by qualified counsel prior to formal submission.
- Strict Professional Guardrails for Attorneys: Processing client materials through public LLMs can constitute a direct breach of an attorney's professional duty of confidentiality. Counsel must formally advise clients against inputting case details into public models to protect case strategy and isolate liability exposure.
Conclusion
The ruling in the Heppner case does not reshape fundamental evidentiary laws; rather, it applies long-standing doctrines of privilege and privacy to the frontiers of generative technology. As enterprises integrate AI into their operational workflows, maintaining an accurate equilibrium between technological agility and regulatory compliance is paramount. The realization that AI chats can serve as evidence in a prosecution underscores a clear directive: proactive digital risk management remains an indispensable asset.

Disclaimer & Copyright: This article is co-authored by Mandy Wu and Yu Yuting. The insights shared are for general compliance trends only and do not constitute formal legal advice.As a specialized cross-border legal institution, Neo-Ark Law Firm provides comprehensive global compliance and rights-protection support for expanding enterprises. For more international legal updates, please visit the Neo-Ark Law Firm Official Websites (https://www.neoarklawyers.com/news).